Advanced
Get better quality
Get better answers by using state-of-the-art components
Background
Our Quickstart guide is meant to get you up and running as quickly as possible. Here we focus on more accurate answers, faster responses and a generally more reliable pipeline. Since there’s no free lunch, the setup is more involved.In summary, this section walks you through the following steps:
- Switch from LLM-based retrieval to vector-based retrieval.
- Set up API keys for the embedder, vector store and reranker.
- Index the codebase.
- Enjoy the improved chat experience.
Better retrieval
Responding to a user query involves two steps: (1) figuring out which files are the most relevant to the user query and (2) passing the content of these files together with the user query to an LLM.LLM-based retrieval
By default, we simply list all the file paths in the codebase and ask an LLM to identify which ones are most relevant to the user query. We expect the LLM to make a decision solely based on the paths. This is suboptimal for multiple reasons:- Enumerating all the file paths might exceed the LLM context.
- The LLM has no visibility into the actual content of the files.
Vector-based retrieval
A more principled way of retrieving relevant files invovles the following steps:- Chunk all the files into relatively equally-sized text snippets.
- Embed the chunks (turn them into float vectors).
- Store the chunks in a vector database.
- At inference time, embed the user query and find its nearest neighbors in the vector database.
- An embedder, which converts text into float vectors.
- A vector store, which stores the embeddings and performs nearest-neighbor search.
- A reranker, which takes the top N nearest neighbors retrieved from the vector score and re-order them based on the relevance to the user query.
Setting up API keys
Embedder API keys
There are multiple third-party providers that offer batch embedding APIs. The plot below shows how well they perform on our benchmark: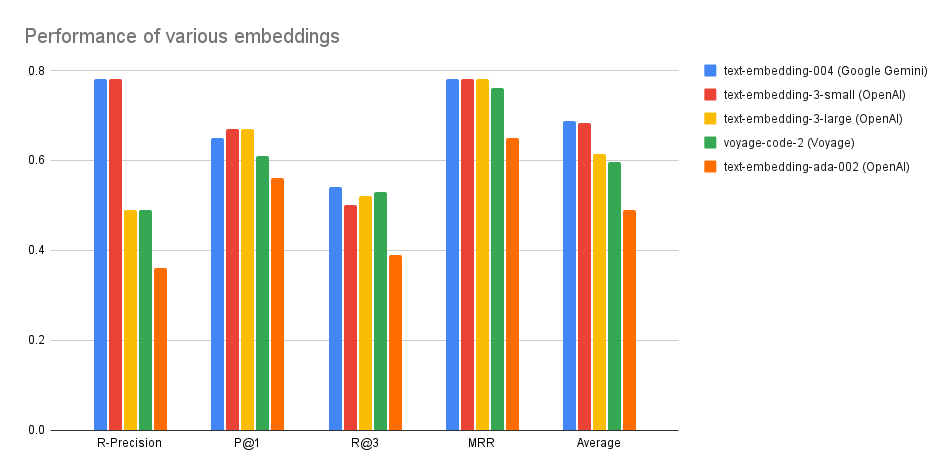 Overall, we recommend using OpenAI’s
Overall, we recommend using OpenAI’s text-embedding-3-small model, which achieves highest quality and has the fastest batch embedding API. Below you will find instructions for each provider:
OpenAI
OpenAI
- Create an API key here.
- Export an environment variable:
Google Gemini
Google Gemini
- Create an API key following these instructions.
- Export it as an environment variable:
Voyage
Voyage
- Create an API key following these instructions.
- Export it as an environment variable:
Vector store keys
Currently, we only support Pinecone as a third-party managed vector database. We are actively working on adding more providers. Here is how you can get it set up:Pinecone
Pinecone
- Create an API key following these instructions.
- Export it as an environment variable:
Reranker API keys
There are multiple third-party providers that offer reranking APIs. The plot below shows how well they perform on our benchmark: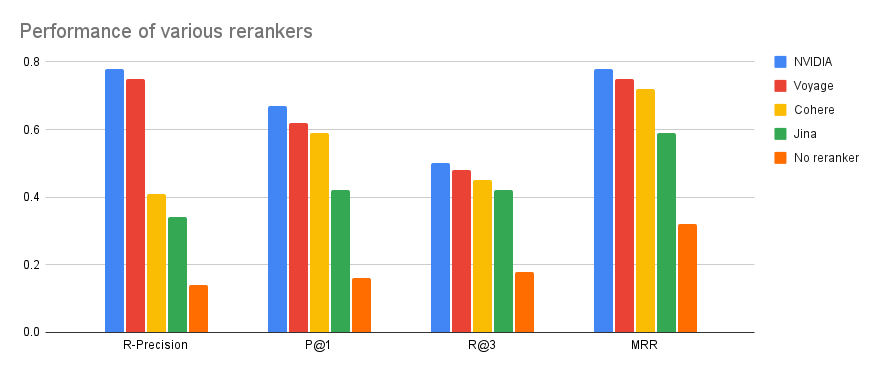 We recommned using NVIDIA. Here are instructions for all the providers:
We recommned using NVIDIA. Here are instructions for all the providers:
NVIDIA
NVIDIA
- Create an API key by following these instructions. Note that API keys are model-specific. We recommend using
nvidia/nv-rerankqa-mistral-4b-v3. - Export an environment variable:
Voyage
Voyage
- Create an API key following these instructions.
- Export it as an environment variable:
Cohere
Cohere
- Create an API key following these instructions.
- Export it as an environment variable:
Jina
Jina
- Create or get your API key following these instructions.
- Export it as an environment variable:
Indexing the codebase
Now that we have set up all the necessary keys, we are ready to index our codebase.- Install Sage. As a prerequisite, you need pipx.
- Index the codebase. For instance, this is how you would index Hugging Face’s Transformers library using OpenAI embeddings and the NVIDIA reranker:
Chatting with the codebase
Once the codebase is indexed, the last piece to configure is the LLM that ingests the relevant files together with the user query to produce a response. We support OpenAI and Anthropic:OpenAI
OpenAI
- Create an API key here.
- Export an environment variable:
Anthropic
Anthropic
- Create an API key following these instructions.
- Export it as an environment variable:
Further customizations
Once you select the desired providers for embedding and reranking, we will use reasonable default models from each. For instance, we default to thetext-embedding-small-3 model from OpenAI. However, you can overwrite these defaults via command-line flags:
This is provider-specific. Make sure that the model belongs to the provider specified via
--embedding-provider. Pass this flag to both sage-index and sage-chat.This is provider-specific. Make sure that the model belongs to the provider specified via
--reranker-provider. Pass this flag to sage-chat.sage-chat and sage-index:
By default, we create a new Pinecone index called
sage. This flag allows you to specify an existing index to reuse.Within a Pinecone index, you can have multiple namespaces. By default, we use the name of the repository (e.g.
huggingface/transformers) for the namespace, but you can customize it via this flag.Pinecone supports hybrid search, which combines dense (embedding-based) retrieval with sparse (BM25) retrieval. This flag represents the weight of dense retrieval. By default, we set it to 1.0 (i.e. fully dense).